C++多线程实践
- C++多线程实践
- C++内存模型和原子类型操作
- std::memory_order初探
- 6种访问次序的说明
- Atomic
- 扩展
- 常见原子类型处理函数
- std::shared_ptr
- 多线程
- 启动线程
- 同步并发操作
- 多任务
- C++11多线程
- 使用方式与POSIX线程接口对比
- 等待线程结束
- 如何向线程函数传参
- 并发算法实现
- C++11线程间共享数据
- 竞争条件
- 避免出现竞争条件
- 互斥锁
- 空类的作用
- 互斥锁的使用示例
- std::lock
- std::lock_guard
- std::unique_lock
- 避免死锁的出现
- 避免持有锁的同时获取另外一把锁
- 避免持有锁的同时调用用户提供的代码
- 按照统一的顺序加锁
- 互斥锁的其他用法
- 无锁数据实现
- Lock-free数据结构
- 设计并发代码
- 将任务分发给多个线程的技术
- 数据的分发
- 递归分发数据
- 使用clang来进行编译时静态死锁检测
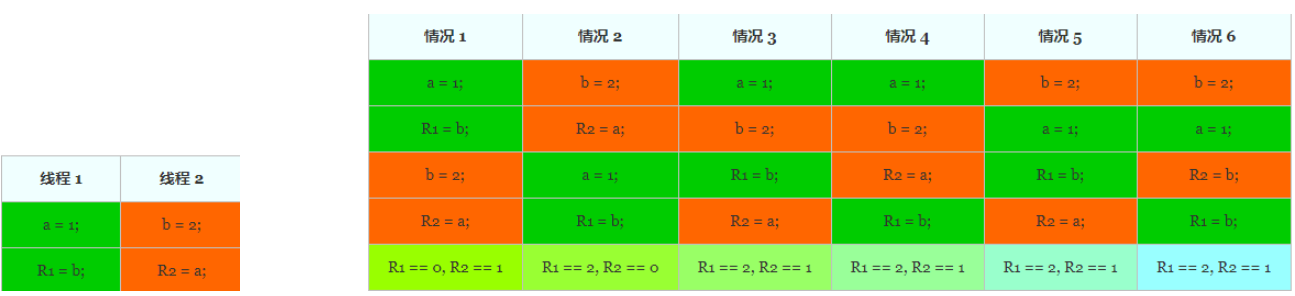
-
-
-
-